This year IBMz skills shortage will be even more critical than in the previous years, while the performance level expectation has never been so high in term of response time and service level driven by round the clock needs of eBAnking, eCommerce, Credits Cards instant payments, international customers, etc… to answer theses needs the overall architecture must be tuned for high performance but is more and more complex with many LPARs, different zSystem configurations such as : storage disks provided by Hitachi Vantara, DELL EMC or IBM, and various options for Disk Flash HPFE , Ficon 16S , z HPF , z Hyperlink, z Hyperwrite , z SuperPav , EasyTier , Flash 3.2T , Cloud Storage HSM …
Since 2014 innovation is booming to speed up zOS Disk response time in order to boost zOS Systems performance. In the following weeks, we will comeback on theses items and show how storage performance is a major contributor to the overall IBMz system performance mainly when Storage response time do not perfectly meet expectation and how automatic storage performance monitoring is probably the best way to meet targets and skill-up z-teams. We organize technical workshops in pertnership with IBM
IBMz Storage Performance : Response time, what is the goal ?
Communication 2 about IBMz storage performance.
In the previous communication we introduced the notion of storage performance as a key contributor of overall IBMz system performance. But what is performance and what is the best way to be sure that the storage is performing as required ?
Response Time is probably the easiest and main parameter to monitor. Of course RT is limited by the technologies involved in the Storage configuration and the path followed by the information during each I/O. So depending on the configuration, the storage unit is able to perform at a given Response Time level.
Many users think that 1ms is a good RT number, but it can be very slow, today zStorage units using Disk Flash HPFE must achieve 0.5ms Response Time maximum in order to answer the CPU in time. In order to avoid CPU waiting time and I/0 retry which will over charge MSU and your z13 or z14 costs, this 0.5ms performance must be stable enough, even when the system is high loaded.
Fine tuning and monitoring are required to avoid erratic Response Time and achieve constant and stable overall performance for each LPAR of your system.
Do you know how far from the 0.5ms response time goal each LPARs is performing and how many CPU time is lost resulting in MSU over charge ?
If we already look ahead and anticipate next step, Response Time goal will be soon around 20µs, achievable with already announced innovations and will required sharp monitoring even more.
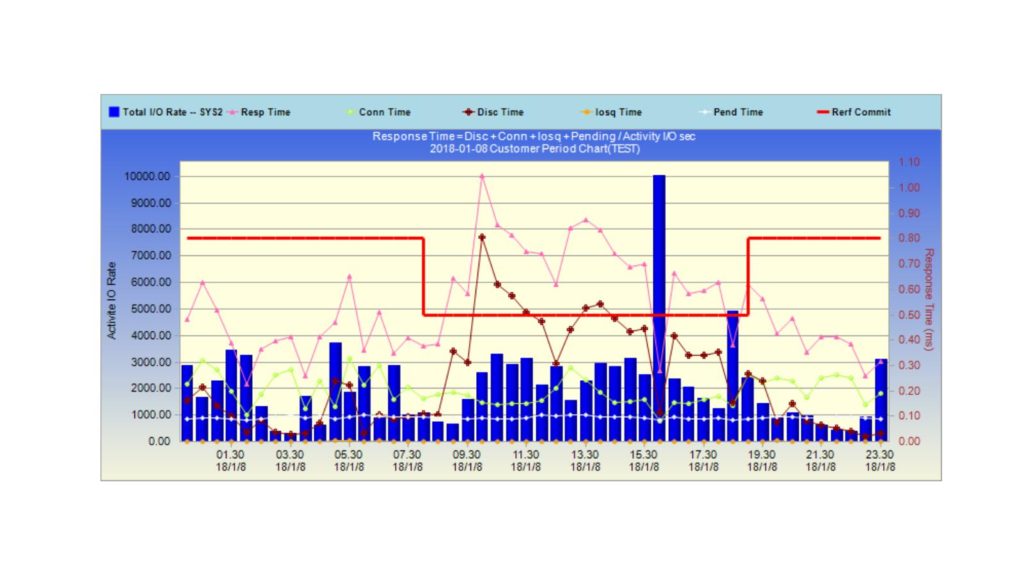
You can see below on an daily automatic monitoring graph of a more than 2000 users LPAR, how the system is performing at 0.4ms RT (pink curve) and suddenly rising up to 1ms RT with disk time x7 (dark curve) and when the RT Commit target is the lowest (red line). The system is just performing the opposite of expected and took a long time to recover. Automatic alert and IA allow in time problem determination, the root cause has been identified and solved.
We are skilled on z-System automatic storage performance measurement, for better mainframe monitoring and if needed problem determination.